Scalability Architecture of Apache Spark
I've been leading several projects recently to scale out financial analytic using Apache Spark -- we've found (like many others!) it works very well. I have used in both data- and compute- dominated scenario us, with the latter being analytics where the computations are more costly than the data movement and reading from disk.
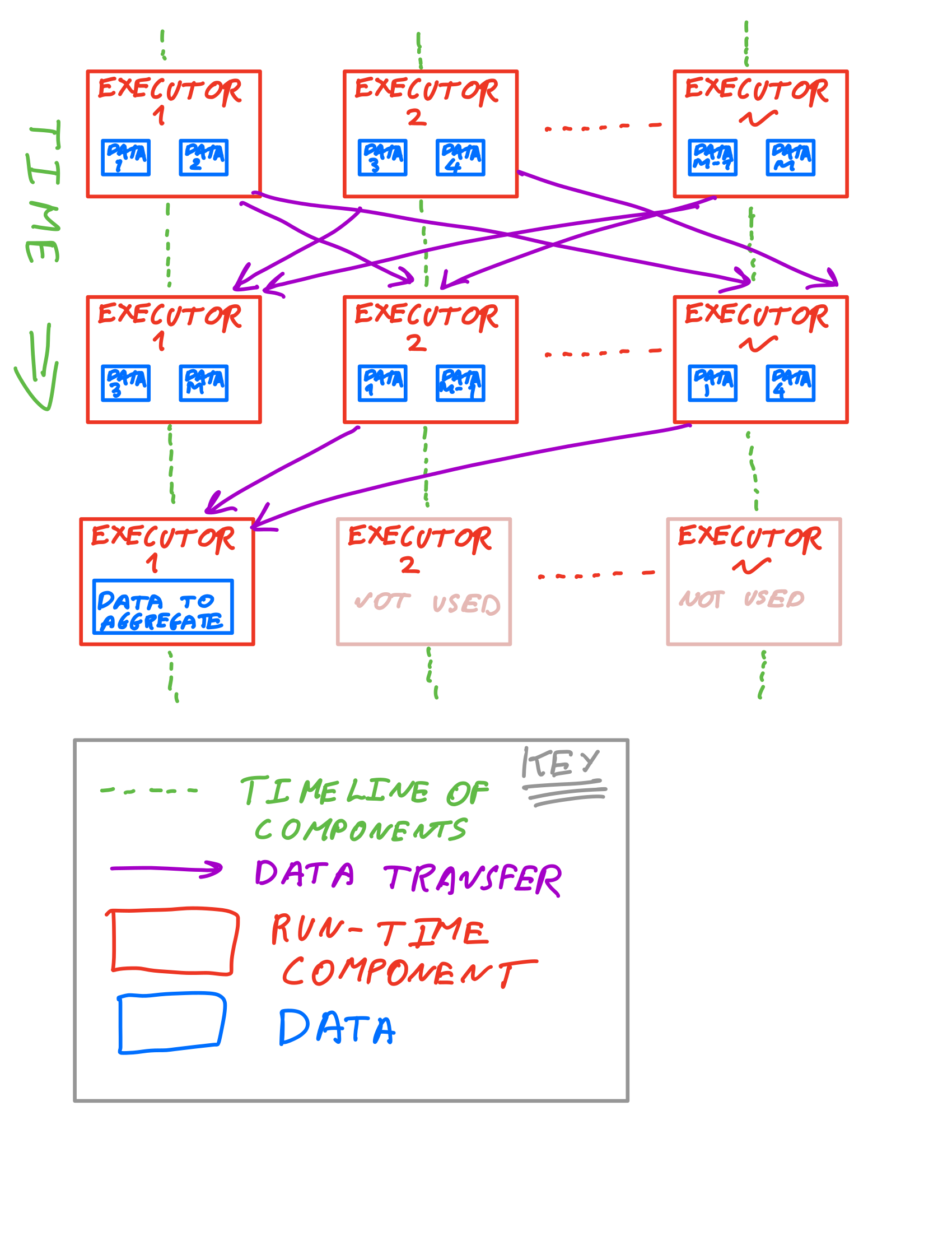
One thing that comes up often is the architecture of Spark scalability. Essentially Spark is a bulk synchronous data parallel processing system, which breaks down to mean:
- Pieces of data (partitions in Spark) have the same operation applied to them in parallel -- this is the data parallel aspect
- All of the processing of one operation/dataset needs to complete before moving onto the next -- this is bulk synchronous aspect
In contrast to Map-Reduce/Hadoop, Spark allows:
- Many stages of processing
- Complex data re-arrangement between the bulk synchronous stages
- Keeping data in memory
Below is a diagram illustrating the Spark scalability architecture: