Quick-to-scale architecture for task-based processing
Quick-to-scale architectures achieve high computational scale with a short latency after the triggering stimulus – in the example described here a scale of 10,000 cores in a few seconds. Their goal is a short time-to-solution with low idling cost. Such architectures are applicable for extremely bursty computational loads, often triggered by a human user. Examples could be a request to re-evaluate a financial portfolio under a new set of assumptions or market observations; or a request to re-analyse complex computer logs to look for a specific signature of a potential problem.
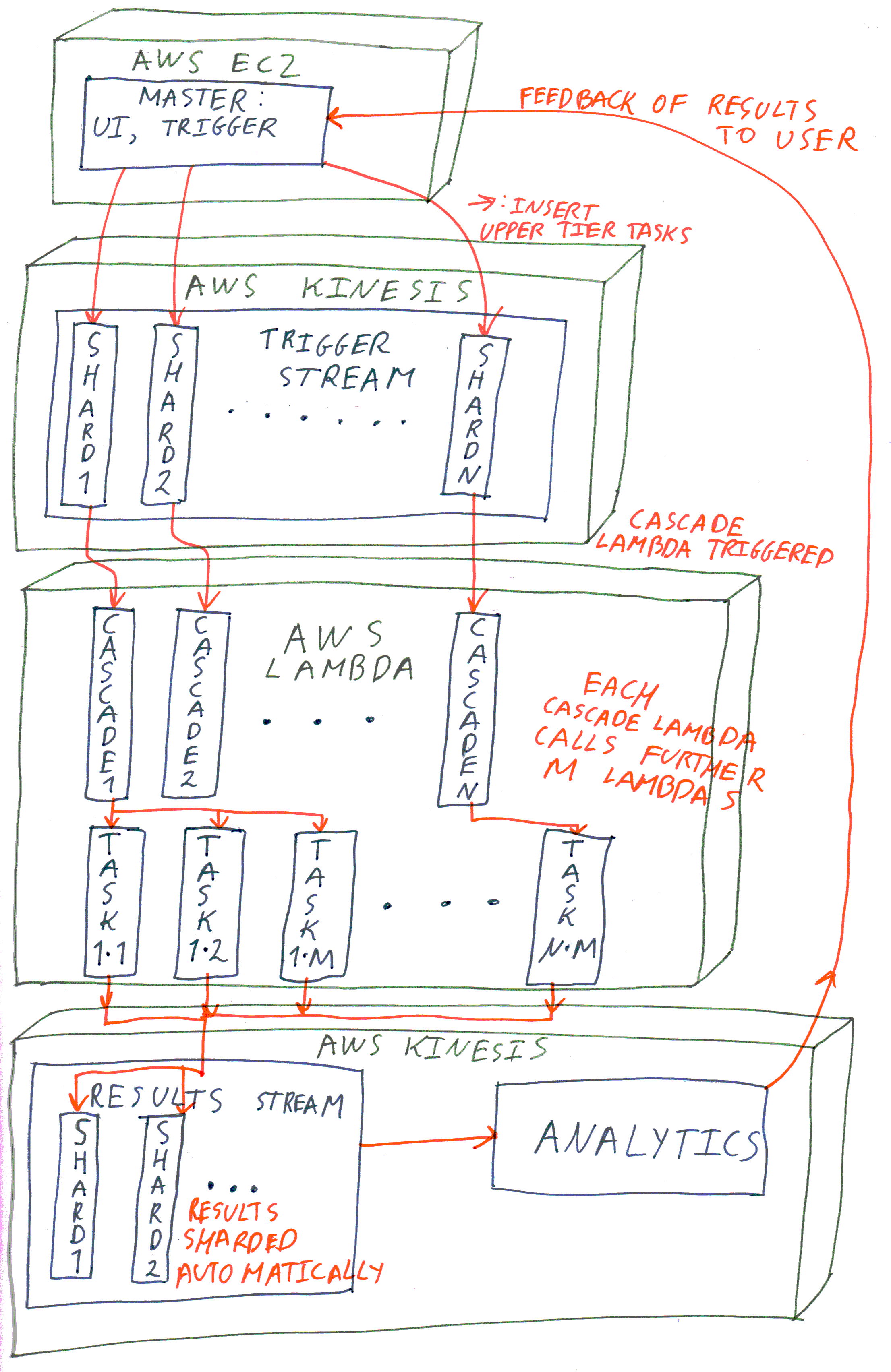
I describe here a quick-to-scale architecture we’ve deployed for several clients over the last year and a half. It is based on Amazon’s AWS services but should be translatable other providers. The goals of this architecture are:
-
Low latency-to-solution for large computational problems, i.e, minimising the wall-clock time between the trigger for computation and the final result being available
-
Reasonably low idling cost
-
Reliable and accurate result aggregation and presentation
The assumption of the architecture is that the computational work to be done can be divided into small tasks with well defined inputs and outputs and without any inter-dependencies between them. Although this is a restrictive requirement for a general task-based system, for many applications where quick-to-scale is relevant, e.g., in finance, this is often an acceptable restriction.
Elements of the architecture
The architecture is built around the following Amazon AWS services:
-
Lambda, a “serverless” compute platform
-
Kinesis Streams, a streaming data platform
-
Kinesis Analytics, a platform for analysing streaming data
-
EC2, a cloud computing platform
One of the candidate architectures we looked at is the cascade of lambda functions as described in: https://aws.amazon.com/blogs/big-data/building-scalable-and-responsive-big-data-interfaces-with-aws-lambda/. This approach however lacked a good mechanism to deal with too many tasks.
The approach we ended up taking makes uses of the stream platform, AWS Kinesis Streams, as a queue for the top level tasks to be computed. The tasks themselves scale up with one level of Lambda Cascade. The use of the streams for queuing tasks has several important advantages:
-
All of the needed tasks can be generated right at the beginning without the need to await for available computational limits (e.g., due to Lambda scaling limitation)
-
Each Kinesis shard has one top-level Lambda function active at a time; as soon as that function is complete, the next task from the queue in this shard can be picked up
-
Tasks can be load-balanced (albeit statically) by manually sharding them
For collecting the output of tasks we also use Kinesis Data Streams, allowing reliable, highly scalable collection of data. The data can easily then be permanently stored in a database, without a need for managing any EC2 servers. Furthermore, the Kinesis Data Analytics can be used to collate and present the results in real-time; this is often a key requirement in quick-to-scale architectures as the end-user is obviously awaiting for those in order to make time-critical business decisions.
Results
As mentioned at the top, the architecture allowed us to scale up to 10,000 cores in a few seconds. The idling costs are dominated by the cost of sufficient number of Kinesis shards which control the top-level task issue rate, which is inversely proportional to the size of the top-level tasks. The usual trade-off of task size applies. Collection of task results using Kinesis Streams and real-time analysis using Kinesis Analytics worked very well too.
The main limitations are associated with Lambda scaling limits applied to Amazon, which can be increased but only up to a certain limit which is short of what the most demanding commercial applications would need; and significant variability in Lambda function start up time which make it difficult to make absolute time guarantees for the completion of computation.