Lazy Code Generation (LzCG) and C++ Expression Templates
Bojan Nikolic <bojan@bnikolic.co.uk>
Table of Contents
1 Summary
In lieu of an abstract, I've put the summary of this paper at the beginning:
- Expression templates in C++ encode the algorithm they perform in the signature of functions to be called
- These signatures can be parsed after the compilation of original code and alternative implementations substituted
-
This allows for substituting an optimised version of the function
after compilation (lazily) by exploiting for example:
- Optimisations not implemented in the compiler
- Knowledge about the precise processor/cache/memory configuration
- Appropriate multi-threading
- Use of an auxiliary processing unit (e.g., GPU)
The other important thing to note is that this paper represents an idea for a yet-to-be-implemented system. If you'd like to support or get involved in the real work of implementing this system please contact me at bojan@bnikolic.co.uk.
2 Introduction
Expression templates are an important feature of C++ that enable very significant optimisation of numerical calculations. They work by allowing the programmer to pass information about an entire expression to be computed, and the types and traits of all of the arguments, to the library designer. The library designer can then use this information to optimise, at compile time, the sequence of operations involved in expression. This technique is used to great effect in Boost's uBLAS library as well as other well known C++ libraries (e.g., the pioneering Blitz++).
Yet, none of the "gold standard" numerical libraries (e.g., ATLAS and FFTW) are written in C++. Why not? There are at least two fundamental reasons. Firstly, what one would call today's standard computing platform (i.e., the x86 platform) in fact represents a huge spectrum of different implementations (different underlying architectures, different cache structures, different main memory speeds, different number of cores) all hiding behind a compatible assembly instruction set. This effect is only compounded by the availability on some machines of powerful auxiliary numerical processing units (sometimes also known as "Graphical Processing Units, GPUs"). All this information about the actual properties of the system to be used is not typically available at the C++ level at compile-time, and therefore can not be used in deciding what code the expression templates should emit.
The second reason is that even when the exact hardware configuration is known, it is often not at all obvious what the best code to emit is: the combination of cache sizes, numbers of cores and memory speeds lead to unpredictable effects, and anyway, the 0x86 assembly language is too "high-level" to be able to understand exactly how and in which order the processor will execute the instructions given to it.
There is also a further, less fundamental reason: the tools we have available are not easy to use and improve. For example, changing, or adding to, the compiler optimisation strategies is only within the realm of a very small circle of experts even when using open source compilers; and, development and de-bugging of expression template libraries is difficult due to sometimes quite verbose syntax and often very verbose error messages. To tackle these last issues, we need to work to improve and simplify our compilers and libraries for writing expression template code.
But, such improvements are not the subject of this paper. Instead, I will stray (a little) from the pure C++ path and consider how, by mixing several of today's widespread technologies, we can achieve optimal numerical performance from C++. The approach I propose is based on two principles: generate the code for the numerically intensive functions at a later stage then the general C++ compilation, and on exactly the hardware that is going to be used for the execution (this is the "lazy" part); and, use tools other then C++ for this lazy-generation of code. What makes this approach easy is expression templates, since their use means that we can decode from the object files for what algorithms we need to generate the code for!
3 How fast numerical libraries achieve their high performance
So, if C++ is not used in libraries that achieve the best performance, which languages are used and how is this high performance achieved? Obviously a variety of approaches are used:
3.1 Hardware detection in object code and deterministic run-time algorithm selection
The idea here is simple: to interrogate the hardware at load-time or run-time and select one of several pre-prepared algorithms already available as object code. These algorithms would have been created to be optimal for some representative systems. This is presumably the approach taken by some of the well-known commercial numerical libraries.
The advantages of such an approach are that:
- A simple, standard, application binary interface (ABI) can be presented to the application which is easily usable from all languages including C, C++ and FORTRAN
- Only object code needs to be distributed
There are however a number of disadvantages:
- Only a certain, small, number of functions (or expressions) can be supported by the library in this way since all of these need to be bundled together with the library
- Only a finite number of alternative algorithms for each function can be shipped while there is a very wide variety of hardware combinations. Therefore the algorithm selected may not be optimal for the particular hardware combination being run
3.2 Stochastic algorithm selection at library build time
By stochastic selection I mean that a number of alternative algorithms for each function to be supported are benchmarked on the target computer and the algorithm with best performance in this benchmark is selected. Because only the object code for the best algorithm needs to be retained, and because the results of previous tests can be used as a guide of which algorithms it is worth trying, a much larger space of algorithms can be explored, leading to potentially better performance. However, for this to be done at build time, the build of the library needs to be made on the target machine.
The advantages of this approach are:
- The standard simple ABI is presented to the application
- The algorithms are tuned for the precise machine on which they are run
The disadvantages are:
- Only a small, pre-defined, number of functions can be supported by the library
- Installation of the library involves a build stage making it potentially more complex
3.3 Stochastic algorithm selection at run time
Here the algorithm selection happens at run time, from a set of pre-prepared object code templates. These templates can represent different families of algorithms and each can have some adjustable parameters which can be iterated over during algorithm selection.
The advantage of this approach is that:
- The algorithm can be tuned on parameters of the functions, e.g., the dimension of a transform operation or the size of a matrix
3.4 Dynamic compilation at run-time
This is the most complex and powerful approach: The expression to be executed is passed (in some sort of code) to a compiler at run-time, and the compiler can then use information about the available hardware to generate code for the expression that has been passed, and then subsequently this run-time generated code is run.
The advantages of this approach are:
- The number of functions or expressions that can be optimised is unlimited as they are interpreted and code for them is generated at run-time
- Precise tuning for the hardware used can be employed
The disadvantages of this approach are:
- It can be hard to integrate correctly with a compiled language like C++
3.5 Automatic use of multi-core and auxiliary processors
Obviously when the computer has a number of cores or when an graphics/auxiliary processing unit is present then large improvements in performance can be achieved by correctly using these resources to the maximum. C-like languages like OpenCL and CUDA are an attempt to provide a programming paradigm that is closer aligned to practicalities of programming of numerical algorithms on many core-systems.
4 Lazy Code Generation
Returning to the subject of numerical performance in C++ programs, how can we easily combine some of the approaches in high performance numerical libraries with good accessibility in C++? The technique I propose here is based on the simple observation: when using expression templates, the signatures of functions provide a full description of the algorithm these functions implement. Further, these signatures are available in the post-compilation object code. This means that after parsing the function signatures present in the object-code files, we can generate new code for these functions and use this new code instead of those generated by the expression templates.
As the lazy-code generation name indicates, this new code for numerically intensive functions can be generated some time after the compilation of the main body of the code, but before the loading and execution of the executable. What advantages can we expect from this approach?
Firstly, by using expression templates to communicate the intended algorithm of numerically intensive functions, we are relying on a standard and widely used technique. If we base our project around an existing expression template library, a default-implementation of each algorithm will already be available, and the program will be runnable on generic hardware without any further intervention. Therefore:
- Leverage very effectively the existing C++ code and tools
- All the standard compile-time syntax and type checking in C++ is enforced on the expressions
- The lazy code generation step is optional and can be skipped during application development
- Programs can be post-optimised for specific hardware without the need to parse original C++ source code
Secondly, the generation of new, optimised code, is done after identifying the precise hardware on which it will be run (but before the loading of the executable code). This means that we can use a wide variety of tools and techniques to generate this optimised code. For example, we can benchmark several different algorithms before selecting the optimal one; or we can target the code for the GPU if it is present on the system.
Thirdly, the code generation does not need to be done from within C++ or C. This has the advantage that we can use different third-party or vendor-specific tools, or we can write our own code generators. The key is that it is unnecessary to modify the C++ compiler itself in order to change the code generated for these numerically intensive loops.
In terms of performance of the generated code, the main disadvantage is that since the code generation is done before run-time, the algorithm can not be tuned to a dynamically decided parameter (e.g., as is usually done for the dimension of the transform in FFT routines). The other disadvantage is the obvious one that we have increased the complexity of the whole build system, but this is diminished somewhat by the fact that expression template generate code is already fully functional and can be used when the machinery for lazy code is not present.
5 A Sketch
Since all of the preceding discussion was somewhat abstract, lets look at some concrete examples to see how expression templates and lazy code generation work. I should prefix this section by a warning that this is not an example of a fully working system, but rather a sketch of how a fully working system might work and where the performance advantage may come from.
In this section we will consider one of the simplest computations: adding two arrays of numbers and storing the result in a third. This example is useful because it is simple to understand even if it is not so important in practice – this is such a common operation that there are many existing high-performance libraries that do this very efficiently. Another thing to keep in mind with these examples is that the performance actually achieved depends significantly on the compiler and the optimisations that it applies to the code. One of the reasons that lazy code generation can be useful is that much of this logic for optimisation can be implemented outside of a traditional compiler. Nevertheless for fair comparison, it is important to always use consistent compilers and turn on optimisations. In this article I've used GCC version 4.4.1 and all code was compiled with "-O3" unless specified otherwise.
A very simple function this can be used for testing performance of the array addition operation (using the Boost.UBLAS library) is as follows:
1: #include <boost/numeric/ublas/vector.hpp> 2: 3: void ublas_t2(size_t n) 4: { 5: boost::numeric::ublas::vector<double> ua1(n), ua2(n), ures(n); 6: for(size_t i=0; i<100; ++i) 7: { 8: ures=ua1+ua2; 9: } 10: }
This is a test function, so it does not do anything useful. In fact a really clever compiler could possibly eliminate this function entirely from a program! The function is however adequate enough for simple performance testing, especially when used with "n" in the region of 106 or so (and the function is certainly not eliminated by GCC).
Since we are using UBLAS which is a linear algebra library, the arrays are named "vectors" but in the present case we are interested in them as simple arrays only.
5.1 Expression template expansion
We now look at the process by which the C++ compiler translates the above function to object code. In broad terms, what a numerical expression template library is concerned with is line 8 of the example above. In particular, the code can be made more efficient by:
- Avoiding generation of a temporary variable
- Carrying out the addition and assignment in a single loop through the code
A useful of understanding this process is to turn off all the optimisations and look at the assembly code generated by the compiler. If we look at the code for the function above that we are using our example, the key line is:
call _ZN5boost7numeric5ublas6vectorIdNS1_15unbounded_arrayIdSaIdEEEEaSINS1_13vector_binaryIS6_S6_NS1_11scalar_plusIddEEEEEERS6_RKNS1_17vector_expressionIT_EE
if we turn the function signature back into standard C++ type syntax, we get an even longer output:
call boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >& boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >::operator=<boost::numeric::ublas::vector_binary<boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::scalar_plus<double, double> > >(boost::numeric::ublas::vector_expression<boost::numeric::ublas::vector_binary<boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::scalar_plus<double, double> > > const&)
This function signature is so long in part because it encodes in one signature both of the operations in line 8 of our example function; i.e., it combines the assignment and addition operations. We can decipher the meaning of the signature as follows:
- First look at the name of the function by looking for the identifier before the "(" token – this is operator=
- As this is a member function, next look for the class that it is the member of – in this case this is ublas::vector<>
- Next look for the return type, which in this case is also ublas::vector<> in this case
- Next look for the template parameters of the function itself – in this case it is ublas::vector_binary<>
- Finally look for the types of the parameters to the function – in this case there is one parameter of type ublas::vector_expression<>
So in broad terms, the function being called is an assignment operator for a ublas::vector<> which assigns directly from a (binary) vector expression. To understand the function signature in detail we need to look at the parameters to the templates. Even for a relatively simple expression like we are considering understand the template type parameters from the printout is almost impossible so it is best to visualise them as a tree, e.g,:

Types in the operator= call with the templates represented as trees (view the image in its own browser window to see it at full resolution). The numbers in square brackets is the character number at which the type starts in the function signature represented in C++ syntax.
For most part the above graph just shows that the assignment, return and expression types are consistent on the precise type of ublas::vector that they deal with. However, one important additional piece of information is that the operation encoded by the binary_expression is just normal addition – this is represented by the scalar_plus type which starts on character 499. So in short the above template type tree tells us that we are have an assignment operator that adds two vectors together!
In the lazy code generation scheme we could simply generate a new version of the assignment operator just described but it is a little simpler to think in terms of free functions. If we follow the call graph from the assignment operator we get to the free function:
void boost::numeric::ublas::vector_assign<boost::numeric::ublas::scalar_assign, boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::vector_binary<boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::scalar_plus<double, double> > >(boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >&, boost::numeric::ublas::vector_expression<boost::numeric::ublas::vector_binary<boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::vector<double, boost::numeric::ublas::unbounded_array<double, std::allocator<double> > >, boost::numeric::ublas::scalar_plus<double, double> > > const&)
which has the types visualisation:
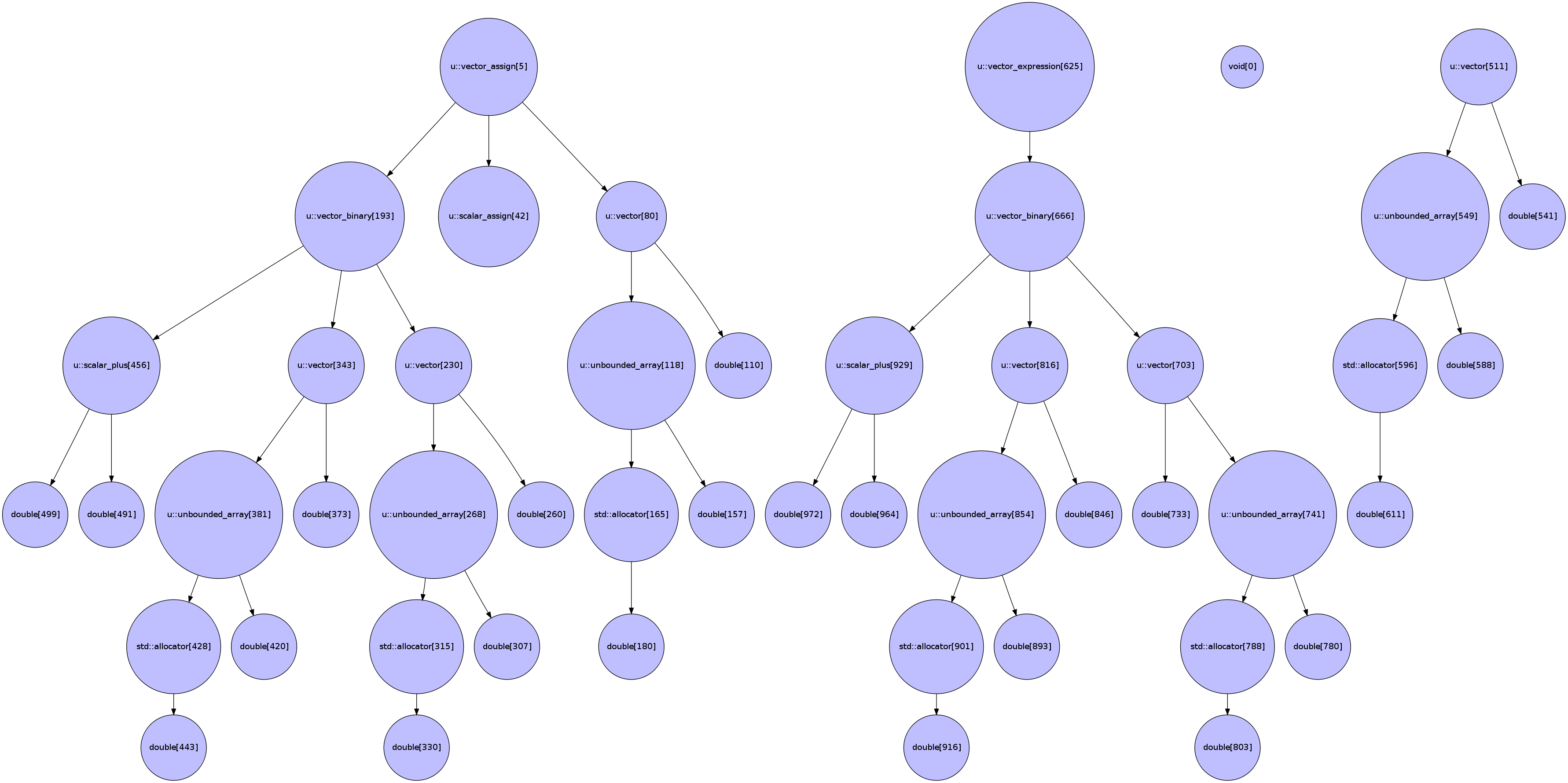
Visualisation of the free function assignment
This is the function for which we will later generate alternative code.
5.2 Object code generated by the compiler
It is instructive to look further into the call graph and the actual assembly instructions generated by the compiler as well as the signatures of the functions being called. If all optimisations are turned off, the generated call graph is rather verbose with many functions being called. In fact even the process of actual addition of two numbers is delegated to a separate function, boost::numeric::ublas::scalar_plus<double, double>::apply(double const&, double const&).
Once optimisations are turned on, essentially all of these additional calls are optimised away, and what remains is a loop with a single addsd instruction carrying out the additions and moving the result to the final location. (There is some additional error checking which does not carry a significant error penalty and can be disabled by defining BOOST_UBLAS_NO_EXCEPTIONS). In fact, this code is close to optimal in many situation as the number of operations that can be carried out is limited by the speed of memory access rather than the computation itself.
5.3 Hand-made alternative
So can we improve the code generated for the simple array addition? One thing to try is using the a SIMD operation (addpd) rather than the individual addsd. Currently there are several ways in which this could be done:
- Improve the compiler to recognise that in this situation a SIMD instruction could have been used
- Modify the template expression library to generate SIMD instructions
- Hand write the function using the addpd instruction
The first choice is hard because, as I argued above, modifying existing compilers is hard to do and one needs to decide on the hardware to be used at the time of compilation of the main body of the code. The second choice is likewise difficult, and for the same reasons.
Hand-writing a function on the other hand is relatively easy once one figures out the signature to use. Here is an a possible example for the function above, based again on Boost.UBLAS, but with a very minor modification to the vector_binary class that makes members expression1() and expression2() public (we need to access them to get to the underlying data!).
#include <pmmintrin.h> #include <boost/numeric/ublas/vector.hpp> namespace boost{ namespace numeric {namespace ublas { // This is example of a hand generated assignment! template<> void vector_assign<boost::numeric::ublas::scalar_assign, boost::numeric::ublas::vector <double, boost::numeric::ublas::unbounded_array <double, std::allocator<double> > >, boost::numeric::ublas::vector_binary <boost::numeric::ublas::vector <double, boost::numeric::ublas::unbounded_array <double, std::allocator<double> > >, boost::numeric::ublas::vector <double, boost::numeric::ublas::unbounded_array <double, std::allocator<double> > >, boost::numeric::ublas::scalar_plus<double, double> > > (boost::numeric::ublas::vector <double, boost::numeric::ublas::unbounded_array <double, std::allocator<double> > >&a, boost::numeric::ublas::vector_expression <boost::numeric::ublas::vector_binary <boost::numeric::ublas::vector <double, boost::numeric::ublas::unbounded_array <double, std::allocator<double> > >, boost::numeric::ublas::vector <double, boost::numeric::ublas::unbounded_array <double, std::allocator<double> > >, boost::numeric::ublas::scalar_plus<double, double> > > const&b) { typedef double v2df __attribute__ ((mode(V2DF))); v2df * dest=(v2df *)&(*a.begin()); const size_t n=b().expression1().size(); const v2df *src1=(const v2df *)&(* b().expression1().begin()); const v2df *src2=(const v2df *)&(* b().expression2().begin()); if (n%2==0) { for(size_t i=0; i<n/2; i++) { dest[i]=__builtin_ia32_addpd(src1[i],src2[i]); } } else { for(size_t i=0; i<n; ++i) { dest[i]=src1[i]+src2[i]; } } } // Close the namespace declaration }}}
There are several important points to note with reference to the above function:
- The function signature is long and difficult to write and understand by hand
- We are using a hardware dependent intrinsic call __builtin_ia32_addpd() – this won't work on most platforms
- The hand-coded function is written as a template specialisation
There is a great advantage in using template specialisation: the compiler decides at link time if the specialised or default template implementation is used (in Linux terms, the template generated function is weak). This means that the object generated from the program can be used as is, or, the key functions can be replaced after the compilation of the main body of the program.
In this paper I am just sketching how lazy code generation would work but it is still worth mentioning that the above hand-code function works about 20% faster with arrays of size of around 1000 elements.
5.4 How would Lazy Code Generation work?
The above hand-coded example might improve performance but it has the disadvantage that it is labour intensive to write and maintain. The aim of lazy code generation is to automate the process of writing these specialisations using the following sequence of logical operations:
- Analyse function signatures in object code to extract signatures of expression templates (this is easily done using nm and c++filt tools)
- Analyse expression template signatures to determine the algorithms that they represent
- Identify functions that represent algorithms that the lazy code generator know how to optimise
- Generate the new code for these functions, possibly experimentally benchmarking different implementations on the available hardware
- Compile and link this code with the original object code to produce an optimised executable
While it will no doubt be substantial amount of work to do implement all of these, it is worth noting that there are some tools already available which can do some of the tasks. For example the Theano (http://deeplearning.net/software/theano/) library for Python allows for dynamically building efficient code for expression trees, including support for GPUs.
6 Publishing History
| Version | Date | Description |
| 1.0 | 5/02/2011 | Initial Version |
Date: 2011-02-05 21:38:56 GMT
HTML generated by org-mode 7.3 in emacs 23