Avoiding Hyperhtreading using numactl
Hyper-threading consists of a single CPU core presenting as two separate CPUs which the OS and applications see as having completely separate state. It is possible to turn off hyper-threading system-wide, but here is how to do it on an application-by-application basis using the numactl utility.
CPU topology representation in Linux is described in these kernel
pages. There
is some useful information on how to interpret this also in this
article by
AWS
as well as on the use of the numactl utility in this article by
nuralmagic.
The fundamental approach is straightforward:
-
Determine which logical CPUs share a core either by parsing
/sys/devices/system/cpu/cpu*/topology/thread_siblings_listdirectory structure or by the usinglstopoutility -
Run an application on subset of available CPUs using the
numactlprogram with--physcpubind=option to avoid the logical CPUs that share single physical core
Example test
Here are some example tests on a laptop CPU. The benchmark program is
simply the 7zip inbuilt bechmark which can be run with 7zz b.
These tests are purely illustrative of the technique using numactl. It is essential to perform your own tests on your own target hardware and applications! The whole point of this article is that effect of hyperthreading is not easy to predict!
Topology of test machine
The test machine has an
i7-1260p
CPU with 4 hyper-threaded performance cores and 8 economy cores for a
total 16 threads. A graphical representation made with lstopo
is below:
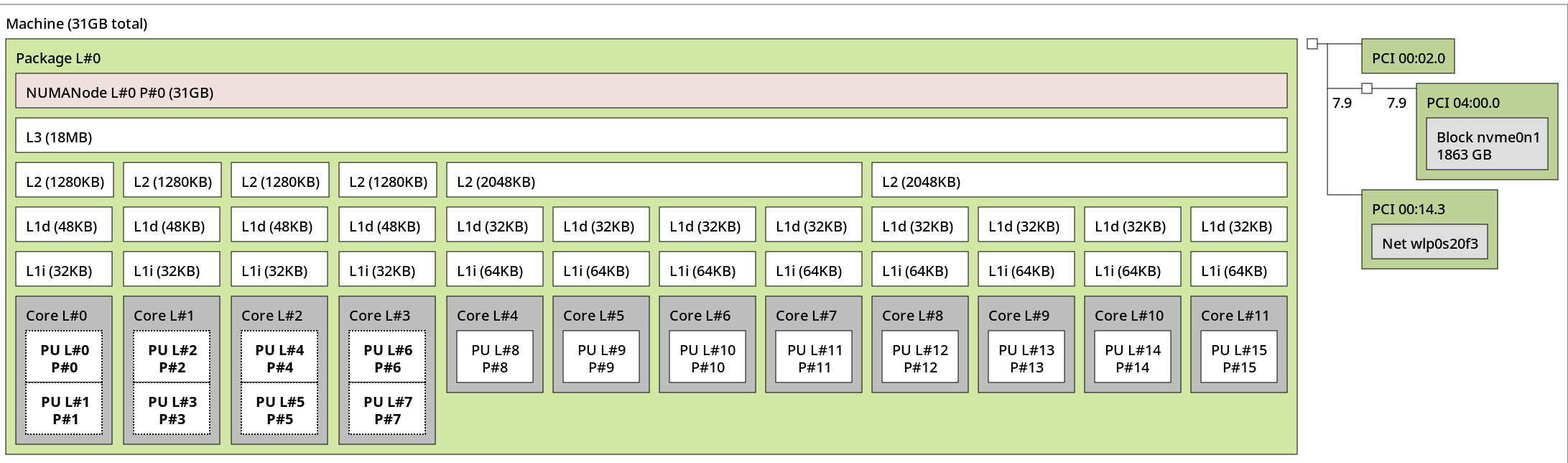
The thread siblings on performance cores are neighbouring CPU numbers:
$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
0-1
Summary of results
On this CPU hyper-threading slows down the 7zip benchmark by about 15%. If avoiding hyperthreading, using two performance cores gives double the performance. Economy cores do not support hyper-threading and using two cores gives about double the performance regardless of the combination of CPUs used.
It is essential to do tests of your own applications on your own hardware as many factors will change the impact of hyperthreading!
Detailed results
Results on Performance Cores
Single “Performance” core benchmark
numactl --physcpubind=0 7zz b
7-Zip (z) 22.01 (x64) : Copyright (c) 1999-2022 Igor Pavlov : 2022-07-15
64-bit locale=en_GB.UTF-8 Threads:16
Compiler: 12.2.0 GCC 12.2.0
Linux : 6.6.56-1-longterm : #1 SMP PREEMPT_DYNAMIC Thu Oct 10 15:20:52 UTC 2024 (67435e5) : x86_64
PageSize:4KB THP:always hwcap:2 hwcap2:2
12th Gen Intel(R) Core(TM) i7-1260P (906A3)
1T CPU Freq (MHz): 1415 1521 1721 2190 2190 2158 1944
RAM size: 31796 MB, # CPU hardware threads: 1 / 16 : 0001
RAM usage: 437 MB, # Benchmark threads: 1
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 4100 100 3981 3989 | 27426 100 2342 2342
23: 4092 100 4185 4170 | 27280 100 2359 2361
24: 3499 100 3763 3763 | 28183 100 2478 2474
25: 2981 100 3408 3404 | 26446 100 2353 2354
---------------------------------- | ------------------------------
Avr: 3668 100 3834 3831 | 27334 100 2383 2383
Tot: 100 3108 3107
Benchmark avoiding hyperthreading
I avoid hyperthreading by pinning the two benchmark threads to CPUs which are on separate cores, i.e., CPUs 0 and 2.
$ numactl --physcpubind=0,2 7zz b
7-Zip (z) 22.01 (x64) : Copyright (c) 1999-2022 Igor Pavlov : 2022-07-15
64-bit locale=en_GB.UTF-8 Threads:16
Compiler: 12.2.0 GCC 12.2.0
Linux : 6.6.56-1-longterm : #1 SMP PREEMPT_DYNAMIC Thu Oct 10 15:20:52 UTC 2024 (67435e5) : x86_64
PageSize:4KB THP:always hwcap:2 hwcap2:2
12th Gen Intel(R) Core(TM) i7-1260P (906A3)
1T CPU Freq (MHz): 1632 1173 1440 2171 2126 2045 2062
1T CPU Freq (MHz): 100% 2009 100% 1640
RAM size: 31796 MB, # CPU hardware threads: 2 / 16 : 0005
RAM usage: 444 MB, # Benchmark threads: 2
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 7543 168 4367 7338 | 45814 200 1956 3912
23: 8319 173 4891 8477 | 48361 200 2094 4186
24: 8079 181 4806 8687 | 39063 200 1718 3429
25: 5865 181 3701 6697 | 37978 200 1692 3380
---------------------------------- | ------------------------------
Avr: 7452 176 4441 7800 | 42804 200 1865 3727
Tot: 188 3153 5763
Forcing hyperthreading
Here I am selecting sibling CPUs 0 and 1, which share a single core and the performance is 10% less than in the non-hyperthreaded scenario:
numactl --physcpubind=0,1 7zz b
7-Zip (z) 22.01 (x64) : Copyright (c) 1999-2022 Igor Pavlov : 2022-07-15
64-bit locale=en_GB.UTF-8 Threads:16
Compiler: 12.2.0 GCC 12.2.0
Linux : 6.6.56-1-longterm : #1 SMP PREEMPT_DYNAMIC Thu Oct 10 15:20:52 UTC 2024 (67435e5) : x86_64
PageSize:4KB THP:always hwcap:2 hwcap2:2
12th Gen Intel(R) Core(TM) i7-1260P (906A3)
1T CPU Freq (MHz): 1798 2130 1862 2104 2150 2137 2125
1T CPU Freq (MHz): 99% 2114 100% 2152
RAM size: 31796 MB, # CPU hardware threads: 2 / 16 : 0003
RAM usage: 444 MB, # Benchmark threads: 2
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 6511 164 3854 6335 | 41278 200 1763 3524
23: 6648 168 4025 6774 | 37844 200 1639 3276
24: 6481 173 4019 6969 | 40424 200 1775 3549
25: 6309 176 4101 7204 | 39108 200 1740 3481
---------------------------------- | ------------------------------
Avr: 6487 170 4000 6820 | 39663 200 1729 3457
Tot: 185 2865 5139
Results on Economy cores
Economy cores are CPUs 8-15 and are not hyper-threaded.
Single Core
numactl --physcpubind=8 7zz b
7-Zip (z) 22.01 (x64) : Copyright (c) 1999-2022 Igor Pavlov : 2022-07-15
64-bit locale=en_GB.UTF-8 Threads:16
Compiler: 12.2.0 GCC 12.2.0
Linux : 6.6.56-1-longterm : #1 SMP PREEMPT_DYNAMIC Thu Oct 10 15:20:52 UTC 2024 (67435e5) : x86_64
PageSize:4KB THP:always hwcap:2 hwcap2:2
12th Gen Intel(R) Core(TM) i7-1260P (906A3)
1T CPU Freq (MHz): 1318 1586 1452 2157 1721 2047 2149
RAM size: 31796 MB, # CPU hardware threads: 1 / 16 : 0100
RAM usage: 437 MB, # Benchmark threads: 1
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 3782 100 3690 3680 | 29019 100 2485 2478
23: 3299 99 3392 3362 | 29115 100 2530 2520
24: 3052 100 3281 3282 | 29324 100 2574 2574
25: 2475 99 2849 2827 | 28162 99 2524 2507
---------------------------------- | ------------------------------
Avr: 3152 100 3303 3288 | 28905 100 2528 2520
Tot: 100 2916 2904
Neighbouring two CPUs
Economy cores are not hyperthreaded so neighbouring CPUs (in this case 8 and 9) are expected to have about the same joint performance as separated CPUs.
numactl --physcpubind=8,9 7zz b
7-Zip (z) 22.01 (x64) : Copyright (c) 1999-2022 Igor Pavlov : 2022-07-15
64-bit locale=en_GB.UTF-8 Threads:16
Compiler: 12.2.0 GCC 12.2.0
Linux : 6.6.56-1-longterm : #1 SMP PREEMPT_DYNAMIC Thu Oct 10 15:20:52 UTC 2024 (67435e5) : x86_64
PageSize:4KB THP:always hwcap:2 hwcap2:2
12th Gen Intel(R) Core(TM) i7-1260P (906A3)
1T CPU Freq (MHz): 1519 1494 1703 2193 2192 2107 2055
1T CPU Freq (MHz): 101% 2109 98% 1912
RAM size: 31796 MB, # CPU hardware threads: 2 / 16 : 0300
RAM usage: 444 MB, # Benchmark threads: 2
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 6476 163 3854 6300 | 46604 199 2000 3979
23: 5790 167 3534 5900 | 45188 199 1966 3911
24: 6280 172 3930 6752 | 45620 198 2020 4005
25: 5889 172 3913 6724 | 43859 199 1963 3904
---------------------------------- | ------------------------------
Avr: 6108 169 3808 6419 | 45318 199 1987 3950
Tot: 184 2897 5184
Not adjacent two CPUs
numactl --physcpubind=8,10 7zz b
7-Zip (z) 22.01 (x64) : Copyright (c) 1999-2022 Igor Pavlov : 2022-07-15
64-bit locale=en_GB.UTF-8 Threads:16
Compiler: 12.2.0 GCC 12.2.0
Linux : 6.6.56-1-longterm : #1 SMP PREEMPT_DYNAMIC Thu Oct 10 15:20:52 UTC 2024 (67435e5) : x86_64
PageSize:4KB THP:always hwcap:2 hwcap2:2
12th Gen Intel(R) Core(TM) i7-1260P (906A3)
1T CPU Freq (MHz): 1536 1449 1444 2187 2193 2164 1965
1T CPU Freq (MHz): 99% 2108 100% 1978
RAM size: 31796 MB, # CPU hardware threads: 2 / 16 : 0500
RAM usage: 444 MB, # Benchmark threads: 2
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 6584 161 3981 6405 | 47833 199 2050 4084
23: 6151 168 3722 6268 | 47703 199 2071 4129
24: 5967 171 3747 6416 | 43583 198 1929 3826
25: 6234 173 4115 7118 | 45644 199 2041 4063
---------------------------------- | ------------------------------
Avr: 6234 168 3891 6552 | 46191 199 2023 4026
Tot: 184 2957 5289