Thoughts on Nextflow
I’ve been using Nextflow a fair amount recently, here are some collected thoughts:
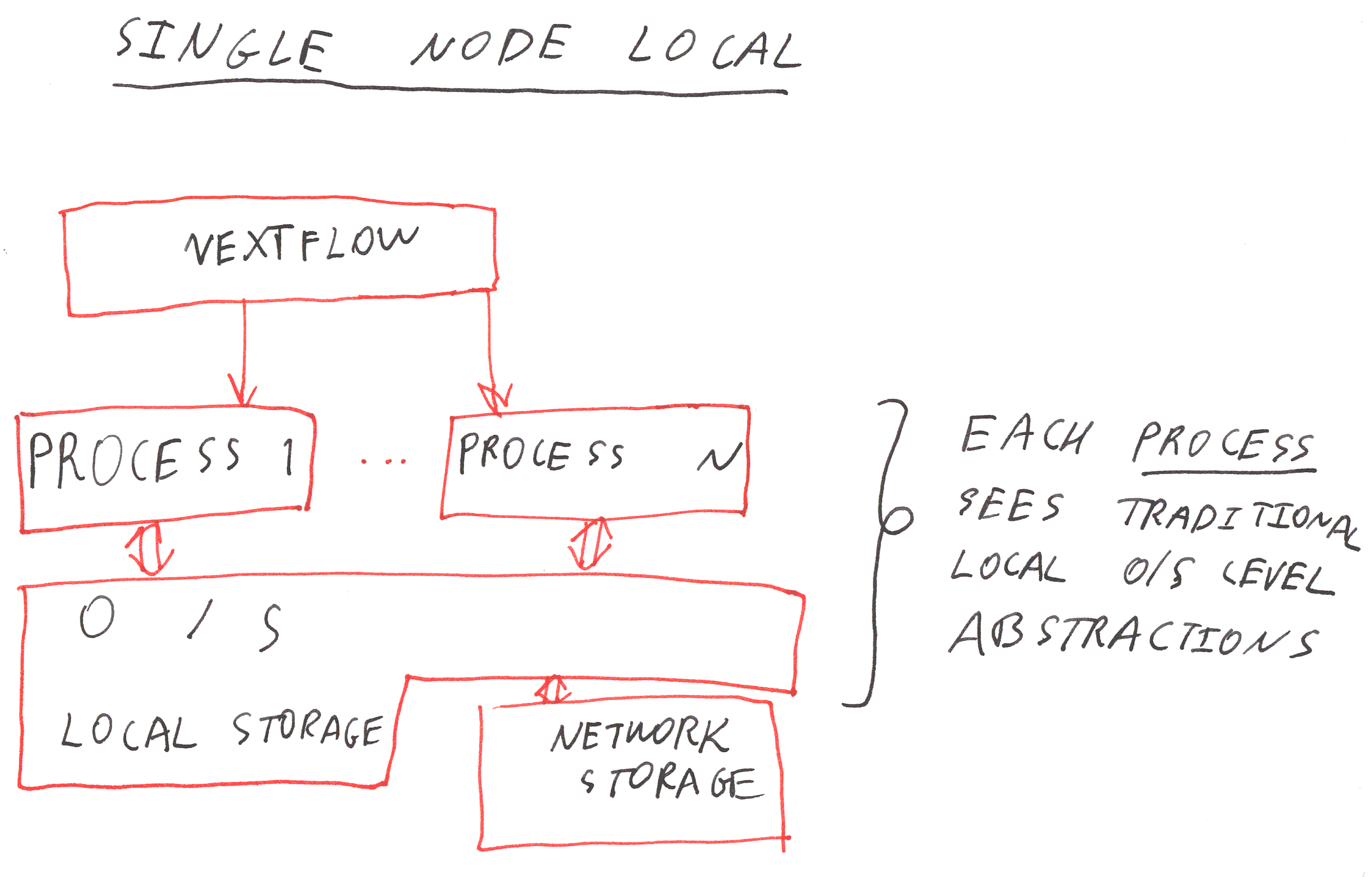
- It is a good system for distributing and organising computation based on processes working in traditional O/S-level abstractions: files, stdin/out, process based parallelism.
- The cache-ing system is (as expected, see my own similar system here ) useful.
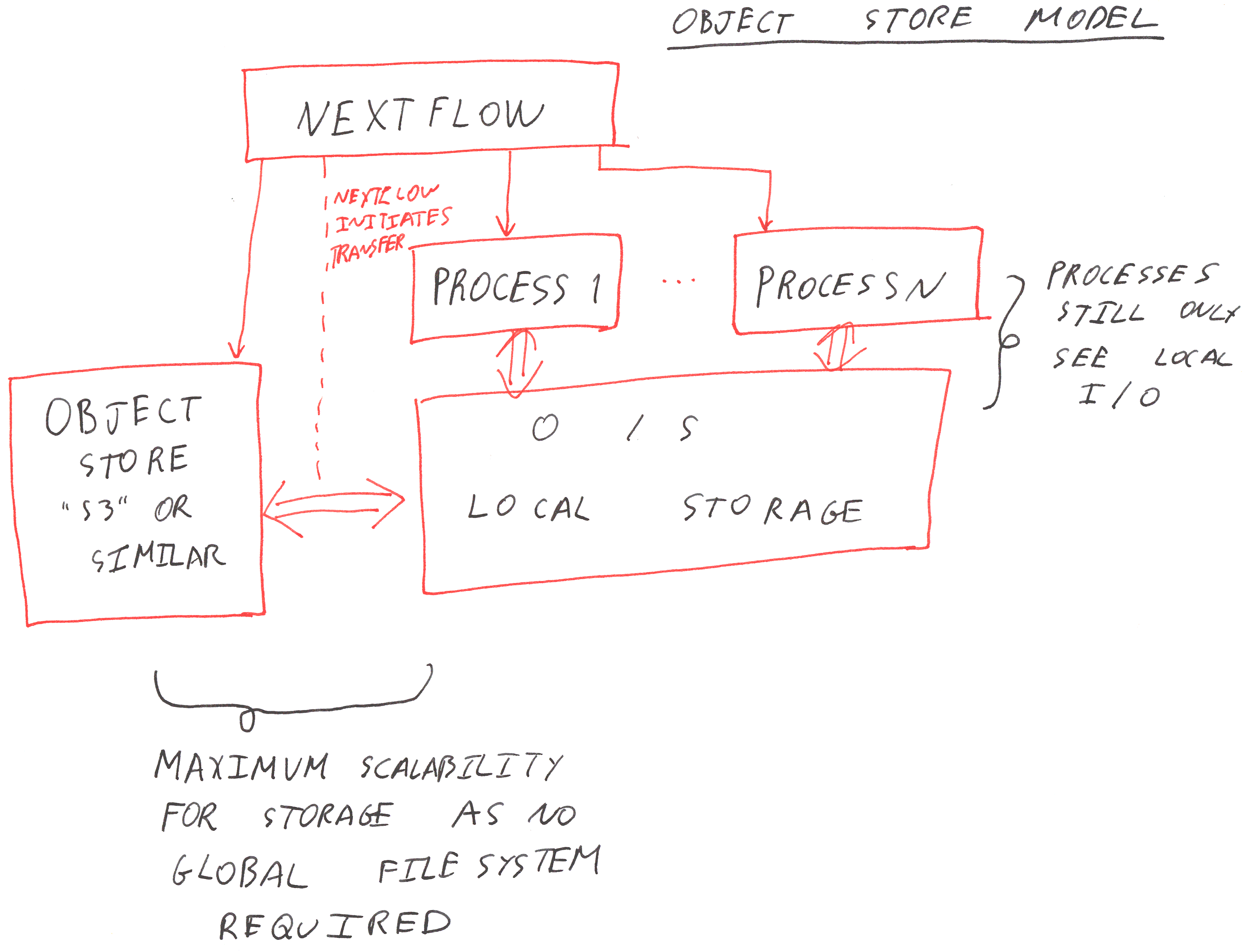
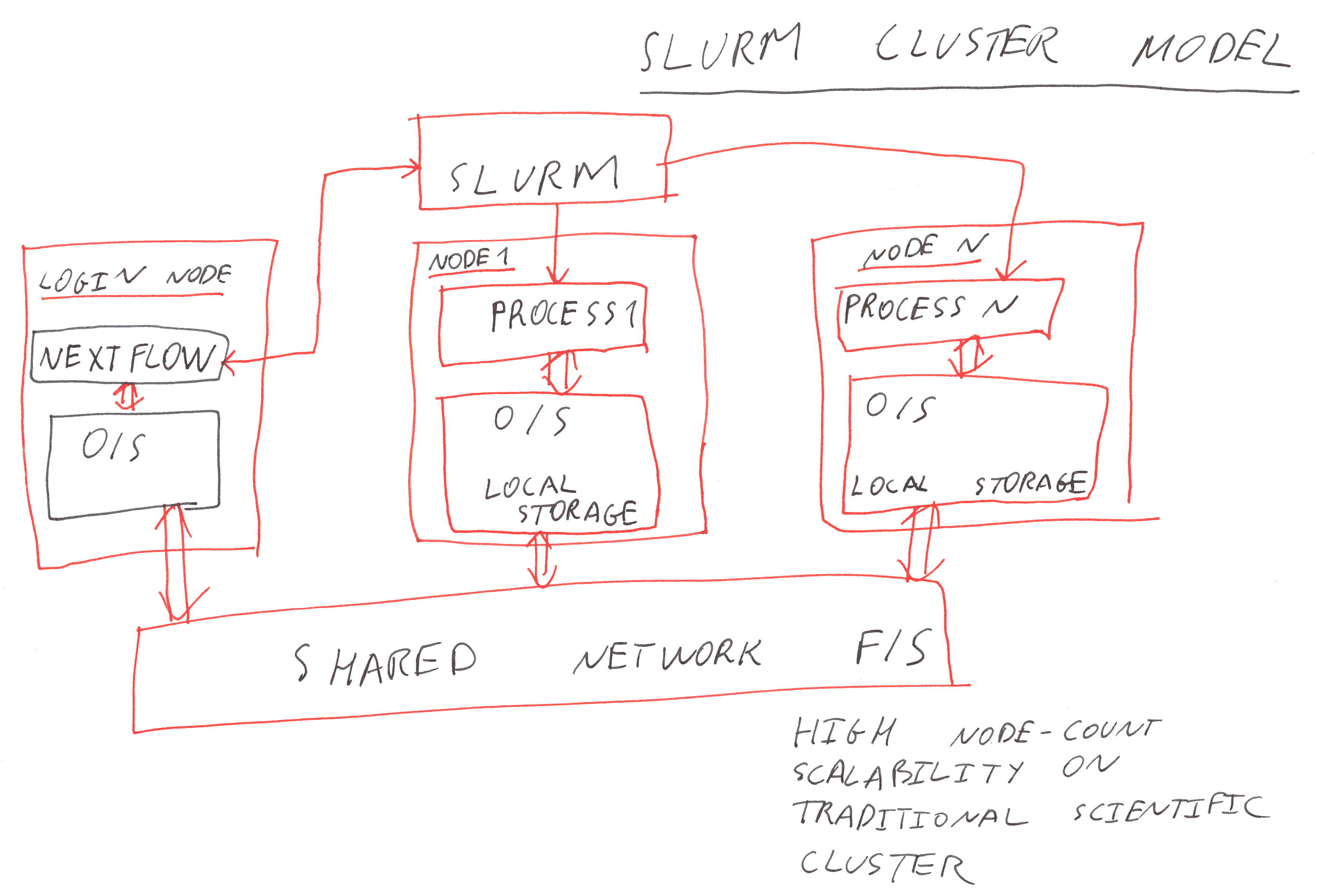
- The integration with cloud auto-scaling clusters of nodes makes it much easier to efficiently scale out into the cloud. Can reduce the time-to-completion by a large factor using this
- Access to file-based intermediate results together with cache/resume is good for exploratory data analysis
- The error messages due to programming errors are not great, this will be confusing for beginners
- Few potential users will know Groovy (and some knowledge is very useful if not required)
- The dichotomy between Groovy functions and dataflow processes and similarly between Groovy variables and dataflow variables will take some for beginners to get used to
- Some edges in the DSL unfortunate like not being able to use the same process twice in a workflow (without reimporting with different name)
Overall a system that you can get work done in straight away. As always develop with a scaled-down problem, then scale-out!