Python forkserver and set_forkserver_preload()
Python comes with the multiprocessing module which allows easy
parallelisation across (as the name suggests) multiple processes. This
is particularly useful for Python because the interpreter is
single-threaded so limited core Python performance improvement can be
achieved by multi-threading1. Modern Python versions (on Linux)
provide three ways of starting the separate processes:
-
Fork()-ing the parent processes and continuing with the same processes image in both parent and child. This method is fast, but potentially unreliable when parent state is complex
-
Spawning the child processes, i.e., fork()-ing and then
execvto replace the process image with a new Python process. This method is reliable but slow, as the processes image is reloaded afresh. -
The forkserver mechanism, which consists of a separate Python server with that has a relatively simple state and which is fork()-ed when a new processes is needed. This method combines the speed of Fork()-ing with good reliability (because the parent being forked is in a simple state).
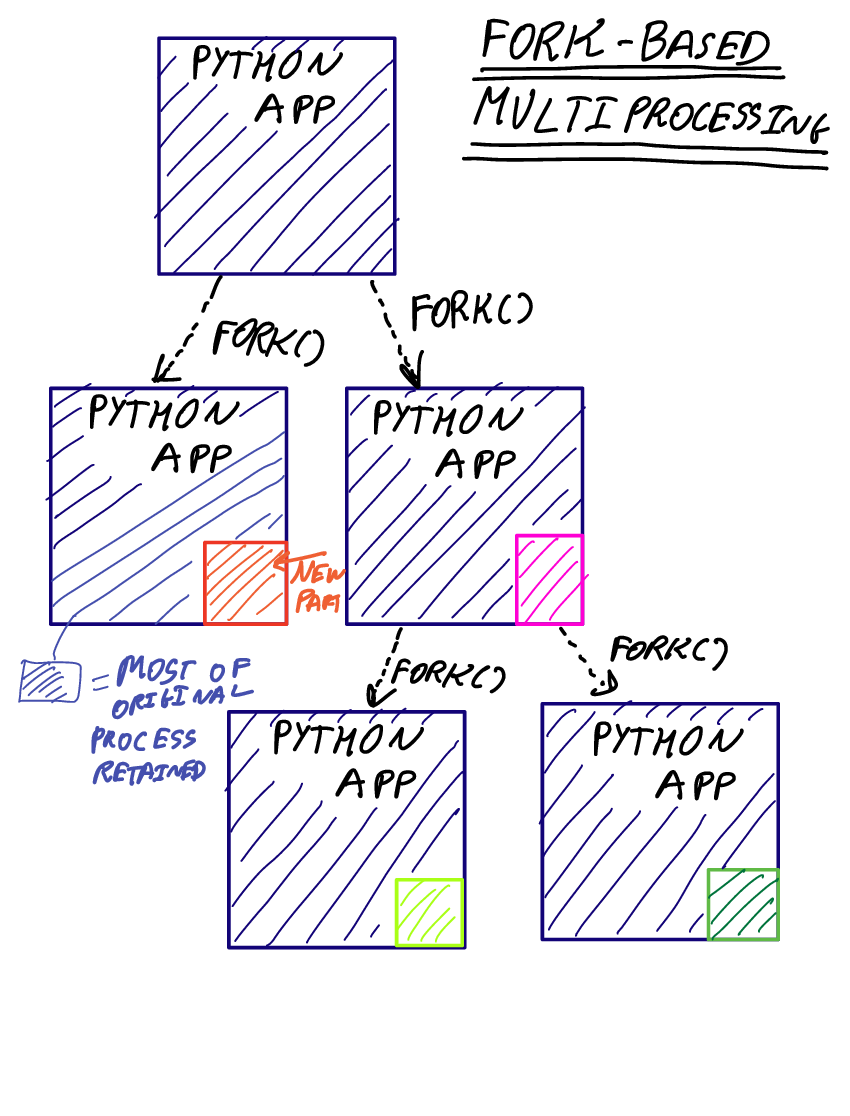
Fork()-ing
The first method, fork()-ing , is illustrated below. Note that children retain a copy of the parent state.
Spawning
The second method, swapn()-ing , is illustrated below. In this method entirely new state is created for each child processes.

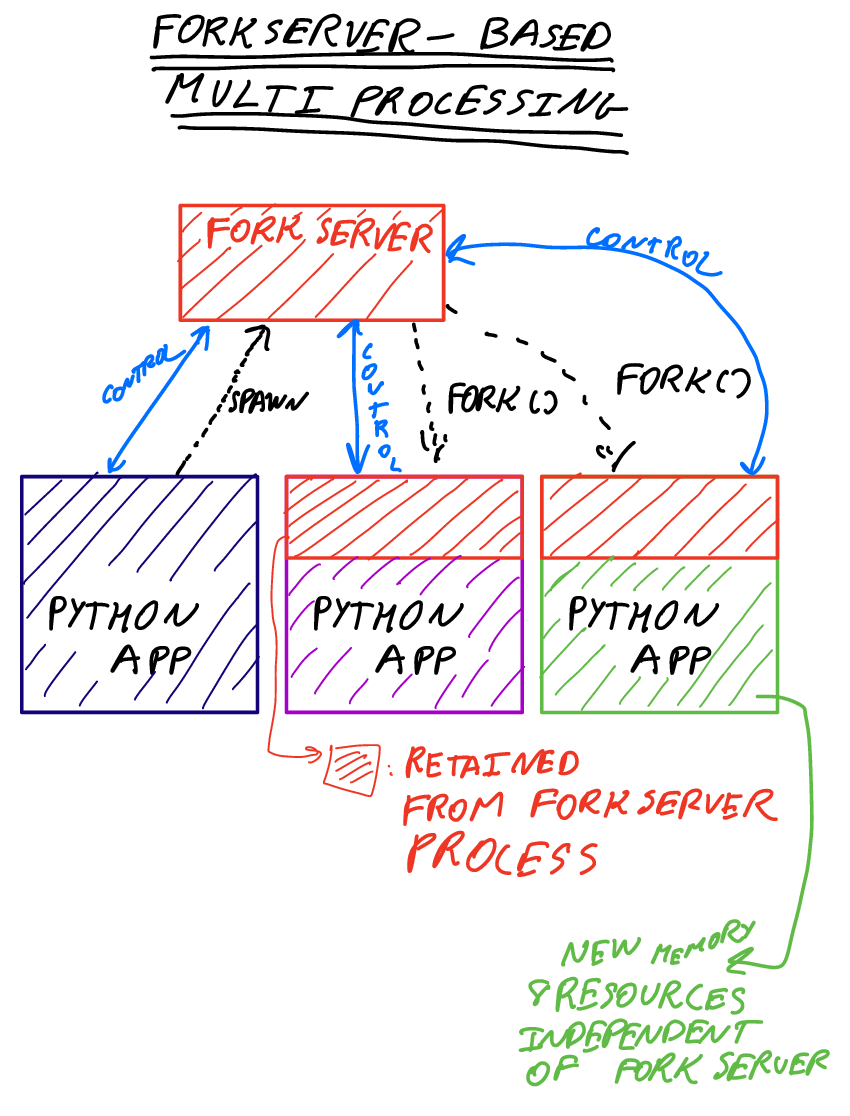
Forkserver
The third method, forkserver, is illustrated below. Note that
children retain a copy of the forkserver state. This state is
intended to be relatively simple, but it is possible to adjust
this through the multiprocess API through the
set_forkserver_preload() method.
set_forkserver_preload()
The purpose of the set_forkserver_preload() API2 is to allow
additions to the forkserver state, specifically to allow some
modules to be imported into the forkserver. These modules will then
be, without any additional performance cost, become available to the
new child processes. In this way substantial performance improvements
can be obtained if there are short-lived child processes that require
complex modules to be imported.
-
See however python-numerical-gil. ↩
-
See the source code ↩