PyTorch Architecture
I’m not involved in development of PyTorch but I do use it and I have introduced it to several (as it happens, non-machine-learning) projects. Others in the projects agree that PyTorch works but they do ask, why does it work? This short note (maybe part of a series) is my attempt to answer that.
Problem PyTorch aims to solve
Obviously I don’t know what the intent was at the beginning (although this article is illuminating) but, retrospectively, what problems does PyTorch solve?
The overall domain of PyTorch is machine learning / neural networks. Within this, PyTorch aims to be (in rough order):
-
Flexible enough to allow easy experimentation and research.
Because machine learning is a rapidly advancing topic where new approaches, sometimes substantially new, are being developed frequently.
-
Intuitive to use for developers with expertise outside of programming
Because people with the insight to develop new machine learning approaches are experts in machine learning, not programming. (e.g., probably, they are very comfortable in MATLAB and Python/NumPy but not Haskell and PTX)
-
Efficient and fast
Because practical machine learning problems are computationally- and data-demanding
Strategy
The strategy that PyTorch adopts to achieve the above aims is as follows:
Flexibility
PyTorch is focused on the machine learning, but the fundamental1 abstractions it exposes are basic numerical array operations. At the basic level, the concept of neural networks is not baked into PyTorch! This in turn allows a great deal of flexibility in building many different types of neural networks as well other machine learning approaches.
This strategy also means that PyTorch can be used very effectively for non-machine learning applications, pretty much anywhere where one would normally use Python/NumPy and lots more elsewhere.
Familiarity
PyTorch programs are written and interpreted like straightforward
Python programs. Normal imperative programming constructs are allowed
(for, if, while etc) and in fact the program looks similar
to what an equivalent MATLAB or Python/NumPy program would look like.
For these reasons they are easy to write and to understand for people with backgrounds in computational physics, statistics or mathematics. I’ve been able to verify this experimentally by introducing colleagues in these fields to PyTorch!
Performance
PyTorch performance is supported by full support for GPU-accelerated asynchronous, batched, operations and for automatic differentiation. Automatic differentiation allows cheap computation of gradients of functions, in turn allowing efficient optimisation (both in machine-learning settings and otherwise!).
Details of Selected Solutions
Here are notes on a couple of the key more detail-level solutions employed by PyTorch:
Automatic Differentiation while maintaining familiarity
PyTorch is supports automatic differentiation while retaining standard Python program semantics by recording (or tracing), at run-time, the graph of operations on its data objects (numerical arrays). See here for details.
When (and if) the user requests the gradients, the graph of operations is traversed backwards to calculate the backward-mode automatic differentiation gradient.
It is possible to visualise the graph of operations recorded by PyTorch, using the torchviz package. Examples can be seen here.
Modelling the distinction between GPUs and CPUs
PyTorch exposes the distinction between GPUs and CPUs to the programmer. The model is that the programmer can select where each data object (numerical array) resides: on GPU memory or CPU memory. Movement of data objects between the two is supported. Computation on objects in GPU memory will be done by the GPU and conversely computation on objects in CPU memory will be done by the CPU.
Operations that mix data objects in the CPU memory with others in GPU memory are not supported, and are (inevitably) caught at run-time. This, unfortunately, does cause some trouble to new comers and somewhat breaks the familiarity strategy.
Investment
There is however, I believe, more to PyTorch than the strategy – there is a large, high quality and sustained investment of programmer effort (I assume on part of Facebook).
Below I compare the graphs of contributions to PyTorch and NumPy. To be clear, NumPy is a hugely successful open source project which is the basis for much of recent numerical and scientific computing. I’ve been using it (and its predecessors numarray and numeric) in academic and commercial project since 2002.
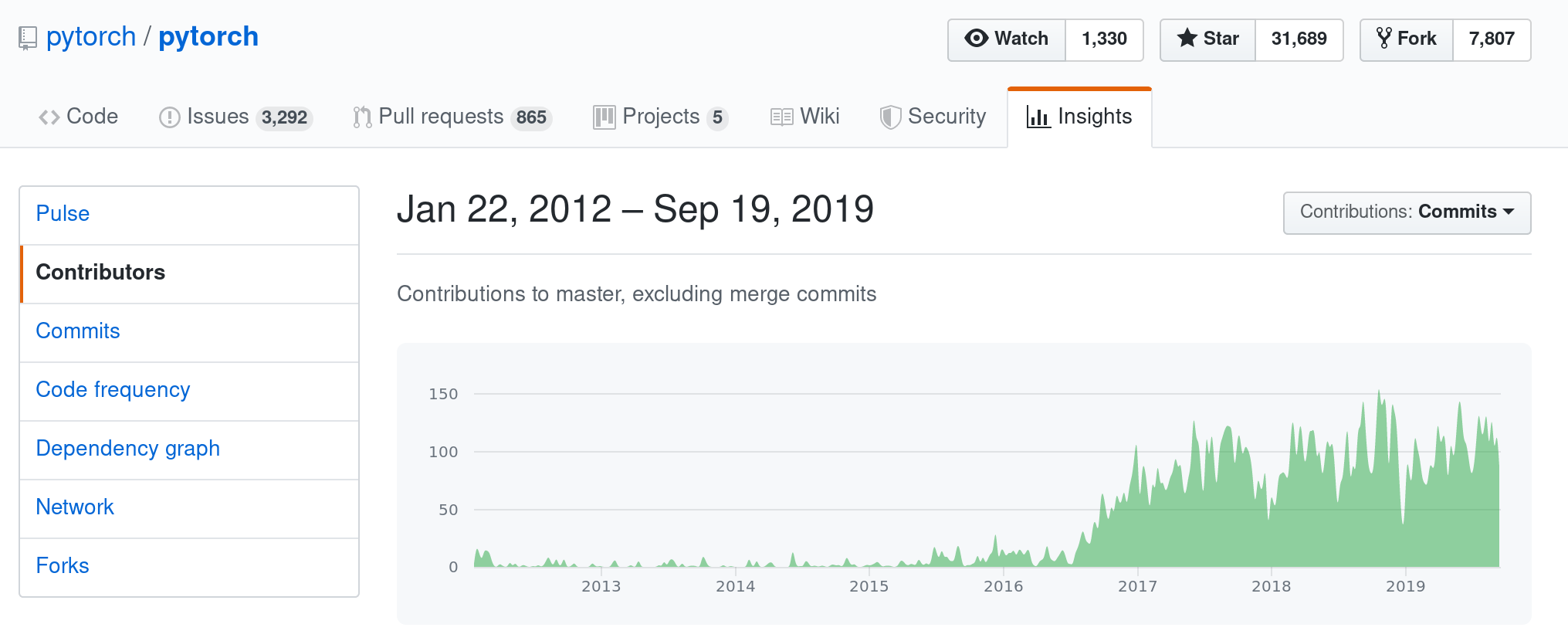
Here is a screen-grab from GitHub of commit frequency by week to PyTorch:
And here is the same for NumPy:
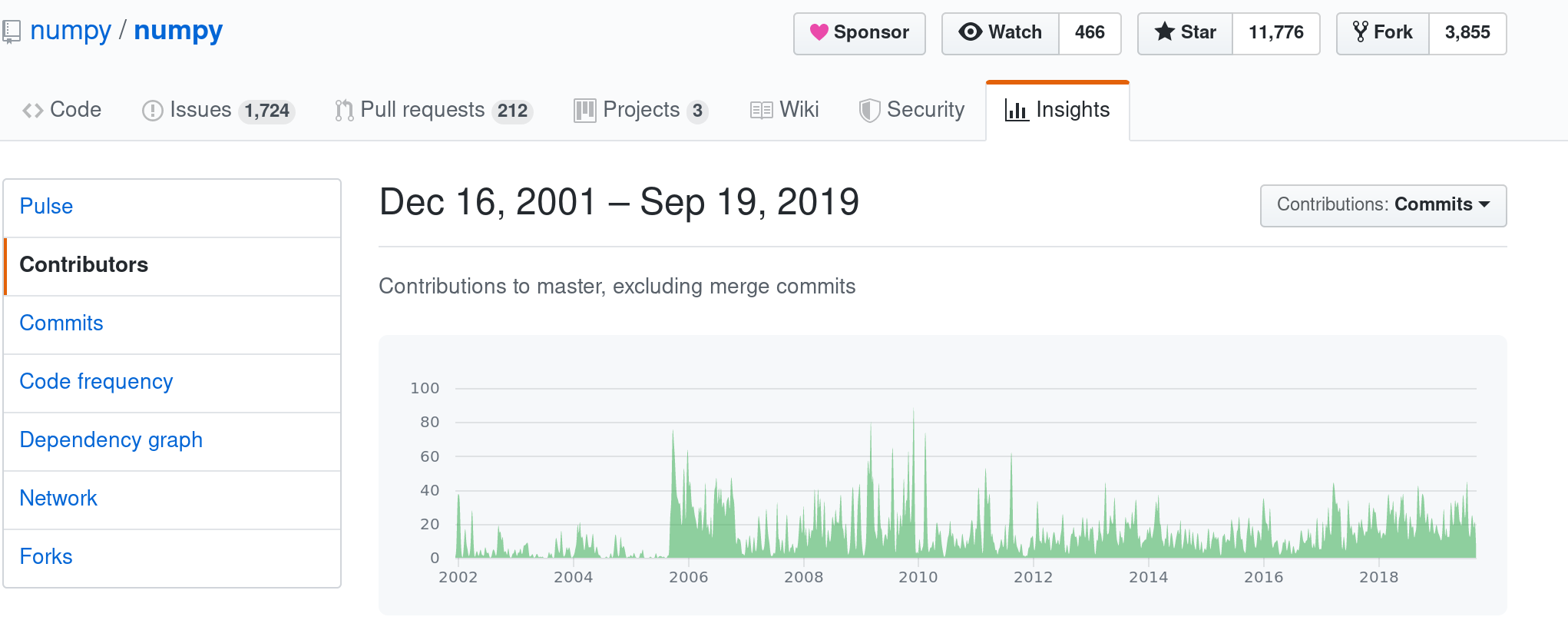
NumPy has received a huge number of commits over a long long period of time. But what is noticeable in PyTorch is the sustained nature high level of contributions: over the last three years, the only weeks with fewer then 50 commits to PyTorch were the weeks around Christmas time! That is a huge investment of time and focused effort.
Summary
PyTorch has focused on solving the right problems (flexibility and familiarity over absolute performance) and this I think is reflected in its growing popularity as well as the successes we’ve had using it. And, although overall performance is very very good it has been further improved (and move into “production” enabled) by more recent addition of JIT compilation.
-
It does also has a higher level interface that is more closely tied to neural networks, but the fundamental level is the low-level interface ↩